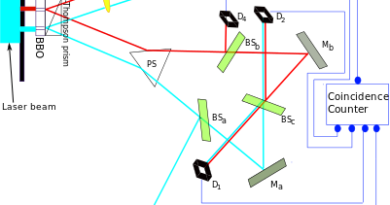
From classical physics to quantum mechanics
Luboš Motl, March 11, 2016
Here’s a way to see in what way quantum mechanics generalizes classical physics – and why it’s foolish to try to look for some «problems» or «cure to problems» in the process of the measurement.
A theory in classical mechanics may be written in terms of the equations for the variables \(x(t),p(t)\)
\[ \frac{dx}{dt} = \frac{\partial H}{\partial p}, \quad \frac{dp}{dt} = -\frac{\partial H}{\partial x} \] for some Hamiltonian function \(H(x,p)\), OK? Now, classical physics allows the objective state at every moment i.e. the functions \(x(t),p(t)\) to be fully determined. But you may always switch to the probabilistic description which is useful and relevant if you don’t know the exact values of \(x(t),p(t)\) – everything that may be known. Introduce the probability distribution \(\rho(x,p)\) on the phase space that is real and normalized,
\[ \int dx\,dp\, \rho(x,p)=1. \] It’s trivial to have many copies of \(x,p\), just add an index, and rename some of the variables etc. Fine. What is the equation obeyed by the probability distribution \(\rho(x,p;t)\)? We are just uncertain about the initial state but we know the exact deterministic equations of motion. So we may unambiguously derive the equation obeyed by the probability distribution \(\rho\). The result is the Liouville equation of statistical mechanics.
How do we derive and what it is? The derivation will be addressed to adult readers who know the Dirac delta-function. If the initial microstate is perfectly known to be \((x,p)=(x_0,p_0)\), then the distribution at that initial moment is
\[ \rho(x,p) = \delta (x-x_0) \delta(p-p_0). \] With this initial state, how does the system evolve? Well, the \(x,p\) variables are known at the beginning and the evolution is deterministic, so they will be known at all times. In other words, the distribution will always be a delta-function located at the right location,
\[ \rho(x,p;t) = \delta [x-x(t)] \delta[p-p(t)] \] What is the differential equation obeyed by \(\rho\)? Calculate the partial derivative with respect to time. You will get, by the Leibniz rule and the rule for the derivative of a composite function,
\[ { \frac{\partial \rho (x,p;t)}{\partial t} = \delta'[x-x(t)] \dot x(t) \delta[p-p(t)]+ \delta[x-x(t)] \delta'[p-p(t)] \dot p(t) } \] or, equivalently (if we realize that \(\rho\) is the delta-function and substitute it back),
\[ \frac{\partial\rho}{\partial t} = \frac{\partial \rho}{\partial x}\dot x(t)+\frac{\partial \rho}{\partial p}\dot p(t). \] This is the Liouville equation for the probabilistic distribution on the phase space, \(\rho\). The funny thing is that this equation is linear in \(\rho\). And because every initial distribution may be written as a continuous combination of such delta-functions and because the final probability should be a linear function of the initial probabilities, we may just combine all the delta-function-based basis vectors \(\rho(x,p;t)\) corresponding to the classical trajectories \(x(t),p(t)\), and we will get a general probability distribution that behaves properly.
In other words, because of the linearity in \(\rho\) and because of the validity of the equation for a basis of functions \(\rho(x,p;t)\), the last displayed equation, the Liouville equation, holds for all distributions \(\rho(x,p;t)\).
Excellent. I emphasize that this Liouville equation is completely determined by the deterministic equations for \(x(t),p(t)\). Aside from the totally universal, mathematical rules of the probability calculus, we didn’t need anything to derive the Liouville equation. Nothing is missing in it. But when we measure an atom’s location to be \(x_1\), then the distribution \(\rho(x,p;t)\) «collapses» because of Bayesian inference. We have learned some detailed information so our uncertainty has decreased. But this collapse doesn’t need any «modifications» of the Liouville equation or further explanations because you may still assume that the underlying physics is a deterministic equation for \(x(t),p(t)\) and all the \(\rho\) stuff was only added to deal with our uncertainty and ignorance. The form of the Liouville equation is exact because it was the probabilistic counterpart directly derived from the deterministic equations for \(x(t),p(t)\) which were exact, too.
What changes in quantum mechanics? The only thing that changes is that \(xp-px=i\hbar\) rather than zero. This has the important consequence that the deterministic picture beneath everything in which \(x(t),p(t)\) are well-defined \(c\)-number functions of time is no longer allowed. But the equation for \(\rho\) is still OK.
Before we switch to quantum mechanics, we may substitute the Hamilton equations to get
\[ \frac{\partial\rho}{\partial t} = \frac{\partial \rho}{\partial x}\frac{\partial H}{\partial p}-\frac{\partial \rho}{\partial p}\frac{\partial H}{\partial x} \] and realize that this form of the Liouville equation may be written in terms of the Poisson bracket
\[ \frac{\partial \rho(x,p;t)}{\partial t} = \{\rho(x,p;t),H(t)\}_{\rm Poisson}. \] That’s great (up to a conventional sign that may differ). This equation may be trusted even in quantum mechanics where you may imagine that \(\rho\) is written as a function (imagine some Taylor expansion, if you have a psychological problem that this is too formal) of \(x,p\). However, \(x,p\) no longer commute, a technical novelty. But the density matrix \(\rho\) in quantum mechanics plays the same role as the probability distribution on the classical phase space in classical physics. You may imagine that the latter is obtained from the former as the Wigner quasiprobability distribution.
Because of the usual, purely mathematically provable relationship between the Poisson brackets and the commutator, we may rewrite the last form of the Liouville equation as the von Neumann equation of quantum mechanics
\[ \frac{d\rho(t)}{dt} = i\hbar [H,\rho(t)] \] that dictates the evolution of the density matrix or operator \(\rho\). (Thankfully, people agree about the sign conventions of the commutator.) It can no longer be derived from a deterministic starting point where \(x(t),p(t)\) are well-defined \(c\)-numbers – they cannot be sharply well-defined because of the uncertainty principle (i.e. nonzero commutator) – but the probabilities still exist and no modifications (let alone «non-unitary terms» etc.) are needed for the measurement. The measurement is just a version of the Bayesian inference. It’s still basically the same thing but this inference must be carefully described in the new quantum formalism.
If you like Schrödinger’s equation, it is not difficult to derive it from the von Neumann equation above. Any Hermitian matrix \(\rho\) may be diagonalized and therefore written as a superposition
\[ \rho = \sum_j p_j \ket{\psi_j}\bra{\psi_j} \] Because the von Neumann equation was linear in \(\rho\), each term in the sum above will evolve «separately from others». So it is enough to know how \(\rho=\ket\psi \bra\psi\) evolves. For this special form of the density matrix, the commutator
\[ [H,\rho] = H\rho — \rho H = H\ket\psi \bra \psi — \ket\psi \bra \psi H \] and these two terms may be nicely interpreted as two terms in the Leibniz rule assuming Schrödinger’s equation
\[ i\hbar \frac{d\ket\psi}{dt} = H\ket\psi \] and its Hermitian conjugate
\[ -i\hbar \frac{d\bra\psi}{dt} = \bra\psi H. \] So if the wave function \(\ket\psi\) obeys this equation (and its conjugate), then the von Neumann equation for \(\rho=\ket\psi\bra\psi\) will follow from that. The implication works in the opposite way as well (Schrödinger’s equation follows from the von Neumann equation if we assume the density matrix to describe a «pure state») – except that the overall phase of \(\ket\psi\) may be changed in a general time-dependent way.
The pure state \(\ket\psi\) corresponds to the «maximum knowledge» in the density matrix \(\rho=\ket\psi\bra\psi\). In quantum mechanics, it still leads to probabilistic predictions for most questions, because of the uncertainty principle. Mixed states are superpositions of terms of the form \(\ket{\psi_i}\bra{\psi_i}\). The coefficients or weights are probabilities and this way of taking mixtures is completely analogous (and, in the \(\hbar\to 0\) limit, reduces) to classical probability distributions that are also «weighted mixtures».
Because we have deduced the quantum equations from the classical ones, it’s as silly as it was in classical physics to demand some «further explanations» of the measurement, some «extra mechanisms» that allow the unambiguous result to be produced. In classical physics, it’s manifestly silly to do so because we may always imagine that the exact positions \(x(t),p(t)\) have always existed – we just didn’t know what they were and that’s why we have used \(\rho\). When we learn, the probability distribution encoding our knowledge suddenly shrinks. End of the story.
In quantum mechanics, we don’t know the exact values \(x(t),p(t)\) at a given time. In fact, we know that no one can know them because they can’t simultaneously exist, thanks to the uncertainty principle. But the probabilistic statements about \(x,p\) do exist and do work, just like they did in classical statistical physics. But the Schrödinger or von Neumann equation is «as complete» and «as perfectly beautiful» as their counterpart in classical physics, the Liouville equation of statistical physics. The latter was ultimately derived (and no adjustments or approximations were needed at all) from the deterministic equations for \(x(t),p(t)\) that the critics of quantum mechanics approve. We just allowed some ignorance on top of the equations for \(x(t),p(t)\) and the Liouville equation followed via the rules of the probability calculus.
So the Liouville equation just can’t be «less satisfactory» than the classical deterministic laws for \(x(t),p(t)\). Nothing is missing. And the von Neumann and Schrödinger equations are exactly analogous equations to the Liouville equation – but in systems where \(xp-px=i\hbar\) is no longer zero. So the von Neumann or Schrödinger equations must unavoidably be complete and perfectly satisfactory, too. They still describe the evolution of some probabilities – and, we must admit because of the imaginary nonzero commutator, complex probability amplitudes. Because of the uncertainty principle, some ignorance and uncertainty – and probabilities strictly between 0 and 100 percent – are unavoidable in quantum mechanics. But the system of laws is exactly as complete as it was in classical statistical physics. No special explanation or mechanism is needed for the measurement because the measurement is still nothing else than a process of the reduction of our ignorance. In this process, \(\rho\) suddenly «shrinks» because it’s one step in Bayesian inference. It has always been.
In classical physics, this Bayesian inference may be thought of as our effort of learning about some «objectively existing truth». In quantum mechanics, no objective truth about the observables may exist because of the uncertainty principle. But the measurement is still a process analogous to the Bayesian inference. It improves our subjective knowledge – shrinks the probability distribution – as a function of the measured quantity. But because of the nonzero commutator, the measurement increases the uncertainty of the observables that «maximally» fail to commute with the measured one. So the measurement reduces (well, eliminates) our uncertainty about the thing we measure, but it affects other quantities and increases our uncertainty about other quantities.
In quantum mechanics, our measurements are not informing us about some «God’s and everyone’s objective truth» (as in classical physics) because none exists. But they’re steps in learning about «our subjective truth» that is damn real for us because all of our lives will depend on the events we perceive. In most practical situations, the truth is «approximately objective» (or «some approximate truth is objective»). Fundamentally, the truth is subjective but equally important for each observer as the objective truth was in classical physics.
But just try to think about someone who says that a «special modification of the Liouville equations of motion» is needed for the event when we look at a die that was tossed and see a number. The probability distribution \(\rho\) collapses. Well, there is nothing magic about this collapse. We are just learning about a property of the die we didn’t know about – but we do know it after the measurement. The sudden collapse represents our learning, the Bayesian inference. In classical physics, we may imagine that what we’re learning is some «objective truth about the observables» that existed independently of all observers and was the «ultimate beacon» for all observers who want to learn about the world. In quantum mechanics, no such «shared objective truth» is possible but it’s still true that the measurement is an event when we’re learning about something and the collapse of the wave function (or density matrix) is no more mysterious than the change of the probabilities after the Bayesian inference that existed even in classical physics.
I am confident – and I saw evidence – that many of you have understood these rather crystal clear facts about the relationship between classical physics, quantum mechanics, measurements, and probabilities.